

It’s an obvious fact that (some) software engineers like (good) computer games. And why wouldn’t they? For people with a “code hard, play hard” mentality, the “play” often gets reflected in the “code”. So, back in 2008 when PortaOne engineers were looking for an internal name for a new telecom service provisioning utility (sometimes called OSS), they decided to explore their gaming-spiced childhoods for cultural references. And as our service provisioning approach evolved from command-line to visual UI and then toward provisioning workflows, those references were there to stay.
Today’s story explains how PortaOne created and groomed ESPF (External Systems Provisioning Framework). We have embedded ESPF with PortaSwitch since MR24 (2011). We call it “Sokoban” (yes, that internal “fun” name), and it’s our solution for communicating changes in subscriber configuration to external third-party systems. You’ll also hear about the overall evolution of our software development techniques, and how provisioning workflows impacted the growth of both PortaSwitch and ESPF.
A Disclaimer (Please Skip If You Are Not a Trademark Attorney)
If by any chance you are a gaming industry trademark attorney, be advised that we use “Sokoban” only as an internal name (and meme). We are not trying to sell any goods or services to anyone using this meme. Officially, “Sokoban” is ESPF. The nickname is just a tribute to a great logic puzzle game and the human minds who created it.
It’s All About Pushin’ the Right Boxes
Since the 1990s, provisioning has been a telecommunications sidekick. The further the industry moved from “black boxes” toward cloud solutions, the more significant the role of telecom provisioning became. Initially, telco staff performed basic provisioning tasks from the command-line interface. Sadly, this approach turned system administrators (“sysadmins”) into a godly caste. Sysadmins (for those of you young enough to not know) were the people who actually “knew the commands”. They could create a workflow of what needed to be achieved right in their head – and (unfortunately) in nobody else’s.
The Age of Programmable Service Provisioning
The next stop was the 2000s and the Age of OSS. Massive vendors (Ericsson, Motorola, Cisco) realized that command lines “ain’t sexy”. Moreover, they were hard to sell, as “non-sysadmins” distrusted them. These “non-techies” were usually the procurement people, the biz execs, the project managers: the ones who made the ultimate decision about which vendor bills to pay. So, the provisioning had to be written as lines of code and then delivered to the operator.
This approach is what enabled the new privileged caste of developers responsible for programming. The end result? A good telecom dashboard looked like the cockpit of a Boeing passenger liner. It cost as much as Boeing, too.
The Age of Low-Code/No-Code
The next generation of provisioning solutions became flow-centered. But while telecom was ahead of the “visual UI revolution” back in the 2000s, it lagged with flows. The “visual UI” paradigm gave the owner of the system a kind of “Swiss Army knife for any life situation” (or so the vendor claimed). On the other hand, the “workflows” paradigm gave them with “building blocks”: pre-coded and self-sufficient functional modules with human-readable UI for setup and configuration.


_interior_(16763231836).jpg){kind=link}
{kind=link}
Workflows dramatically decrease the amount of knowledge a system manager needs to use the system. Instead of learning a dozen functions, the manager now only needs to know “what should be done”, in business terms. The system then provides the visualized “building blocks” that allow the manager to do it. (Imagine a kind of modern disguise for modules and libraries with easy-to-use visual UI.) In the early 2000s, Boomi (Dell Boomi since 2010) from Pennsylvania was the first to bring this idea mainstream. In 2010, IFTTT from San Francisco created their first “if this, then that” automation algorithms. (Hence the company’s name.) Zapier followed with their “zaps” and “paths” in 2012. This all started a low-code and no-code boom.
Telecom Falls Behind in Provisioning Workflows
Interestingly, telecom was initially reluctant to adopt the workflows approach to their daily business tasks. Why? Because, objectively, a modern telco (even when smaller-scale) is rarely a one-vendor organization. So, to implement any actionable provisioning workflows, “someone”, usually the customer, has to create the “lubrication layer”. (And if not the customer, then the least expensive and most flexible vendor in the value chain – which, for some reason, 😉 tends to be PortaOne.) This layer makes information from all the various systems of the customer’s ecosystem “readable” to the OSS and to any standalone billing or provisioning systems.
Welcome ESPF!
Like every solution from PortaOne, ESPF appeared because our business was growing. At first, we targeted VoIP operators and ISPs with PortaSwitch. Calls (or Internet sessions) went through in real-time and usually with the RADIUS authorization. But, with time, we started supporting “things behind the voice calls”. And among the first were GSM mobile networks, IPTV, and messaging.
You could describe the usual relationship in VoIP between billing, service provisioning, and the system that provides the service as “pull”. Pull means that the network equipment asks for authorization from the billing system each time a user attempts to use the service. An example of this could be when they make a voice call or connect to the Internet. The “authorization” comes as a response to a pull request.
How the OTT Solution (Think: Netflix or HBO) Is Different from the Rest of the Telco Billing Crowd in Provisioning Workflows
But here’s the thing. OTT systems such as IPTV (hello, DRM and rightsholder royalties management) are more self-contained. They prefer to get subscriber information from the OSS, then store it locally. For example, with IPTV, you don’t need “a confirmation from billing” each time a customer opens HBO to verify whether the customer really did buy the right subscription plan. Instead, the OTT system can deliver this confirmation once, when the plan is changed – which might happen a few times a year.
So, at PortaOne, we needed a solution that allowed easy information flow between PortaSwitch and these external third-party systems. Thus: ESPF.
Why Sokoban, and How It Relates to Provisioning Workflows
Coding projects should have a name that inspires the people who code them. To that end, our team started thinking about the best name for a framework that enabled the obtaining and handling of billing events and then pushed them into various external systems. “Provisioning reminds me of logistics applied to the digital world,” reasons Serhiy Leschenko, the PortaOne developer who has been in charge of ESPF since the project’s inception. So Serhiy and the team started calling the new module “Sokoban”, after the legendary Japanese logistics game from the 1980s.

Sokoban was legendary in computer gaming (before it went mainstream). Spoiler alert: do not click this link if you are not planning to kill today’s productivity with several hours of nostalgia gaming. (Image from Wikipedia.)
{kind=link}
How Is Sokoban Relevant to Provisioning Workflows?
Hiroyuki Imabayashi created Sokoban in 1981 for Thinking Rabbit in Takarazuka, a mid-sized town on Honshu island in Central Japan. In addition to Thinking Rabbit, Takarazuka is also home to Takarazuka Revue – a Japanese all-female musical theater famous on YouTube.
Sokoban became an international hit. It was so popular that, in the Modern Age, a new team of developers created an open-source GitHub repository for it and then ported it to Android and iOS. The mathematical puzzles Sokoban presents are so good that scientists featured them in research published by the Computational Geometry Journal. And, just like Sokoban, our ESPF helps customers “push the boxes” that contain provisioning events among various “storage locations”. (Those locations being the different external systems housing these events.)
Gearman, and How We “Farmed Out” Provisioning Workflows
Growing ESPF and implementing new features for it required lots of billable hours. Around that time (specifically, 2014 to 2018), we saw the clients who use PortaSwitch as a “master source” of customer configuration data. And we were increasingly using that data to provide more and more services. That’s how we realized we needed more handlers and more automation, preferably done by a third party.
Our first problem to tackle was how to enable more provisioning processes to run at the same time. (For example, when an operator needs to provision five different external systems.) Fortunately, we stumbled upon Gearman, a tremendous open-source tool that solves a generic task: “farming out work to other machines”.
Regrettably, there was a problem with Gearman. While it effectively distributes the workload, it doesn’t provide sufficient and ready-to-use remedies for those “external system not responding” or “server timeout” situations. The tool simply executes the code, and doesn’t care what’s inside. So instead, those situations had to be handled by the code that runs inside Gearman. That created a new dilemma: code this functionality inside every new provisioning adapter executed via Gearman (read: extra cost), or continue searching for a suitable solution.
Unlocking the Platform. Hello, Webhooks!
Things went fast and smooth when the “handler” or “adapter” for a third-party system was there. But that adapter required a particular procedure to appear. Customers had to follow a standard FR path: the code would become a part of the PortaSwitch codebase, and would appear in the next MR.
So the line of thinking with ESPF 1.2 (enforced by Gearman by that time) was to open the system for third parties. Since the most complex part of creating a provisioning adapter is in the realm of the external systems, it makes sense to leave that part to those with the most experience. And that’s the in-house teams or third-party developers who specialize in those systems.
Many customers wanted to code the handler/adapter themselves and (most importantly) to be able to independently and quickly change its logic afterward. But to allow for that, the developer would need direct access to the PortaSwitch servers, with admin privileges to boot. Unsurprisingly, the operations team was not so eager to allow this.
How a Customer Inspired Us to Look Further (and Deeper)
SWIFT Networks, our customer from Nigeria, acquired a local wireless telco license and LTE network equipment from Huawei. After that, they needing a billing system – on a “one month and we are in production” deadline. (Hello, monolithic architecture!) So, Huawei suggested they contact us.
We delivered what SWIFT wanted. But completing this task required us to create a provisioning handler for Huawei HLR. So, we assembled a dedicated team of PortaOne engineers, and did it all in a (seemingly) impossible two-month time frame. Proud of our accomplishment, we started to think: “If we got two such projects at the same time, could we pull it off?”
That’s when it clicked. We realized we could enable customers to do billing system adjustments themselves. And in a matter of weeks, not months. An improvement like that would give us a unique competitive advantage. But the idea raised a new question: How?
Webhooks v. API
Around that time, webhooks became an increasingly popular technology. Webhooks are similar to the API concept: they allow a piece of code to be invoked upon some event or condition, e.g., “when the customer’s invoice becomes overdue, call the program that will update the customer’s status in the CRM and create a task for customer’s account manager to follow up.”
The difference is that API is typically bound by specific technology (e.g., SOAP or REST) or even a programming language. A webhook packs the instruction to call an external code into a basic HTTP request. In that way, it becomes a “least common denominator” between various servers, technologies, and programming languages. “Real” apps in Java or Python, running on a customer’s physical server or inside something like Google Cloud Run, can process webhooks. Or, it can be an applet inside a CRM application, a no-code/low-code integration platform like Zapier, or even some Cobol code running on 😂AS/400 mainframe.
As one publication explains: “API does stuff when you ask it to, while a webhook does stuff on its own when certain criteria are met, or scenarios takes place.” In short, webhooks make writing ESPF adapters possible in any suitable programming language. From there, ESPF would simply send a request to a third-party web server, launching the code. Our team, or even the customer, can write the code in PHP, NodeJS, .NET altogether; a simple “drag-and-click” would perform the task.
Ensuring Flexibility without Affecting Security
Using webhooks also addressed another significant pain: the need to change some code directly on the PortaSwitch server. How do we maintain these adapters on an external platform like a web server or cloud execution environment? With webhooks (even for a production environment), third-party developers can create and maintain their code in AWS Lambda or a low-code platform such as Zapier or Boomi. That gives us a short “learning curve” without security risks.
A Question Still Unanswered by Webhooks
Still, one more element in the puzzle remained unsolved. A provisioning process usually requires making changes to multiple data records in several external systems. And, by the nature of the Internet, there is a chance something could happen in the middle of a transaction. Think: server outage, network congestion, or Facebookageddon.
So what should our provisioning script do if it already activated your SIM card, but the PCRF (a component that controls how fast and much you can download) became suddenly unavailable? Should it keep trying? If so, for how long? And what happens when the script keeps pushing for eight straight hours and the server, where it runs, restarts? That’s why the script needs to somehow skip the “already done” SIM card activation and proceed directly with assigning a tariff plan in PCRF.
Writing code that correctly handles all these “what if” conditions requires a senior developer. In fact, it requires a senior developer with battle scars from previous failures. And those are a very scarce resource. But allowing a junior developer to write code (that works well only in “perfect” conditions) would overburden the operations team. This situation brings us to Temporal.
Discovering Temporal.io: From Burning Man to a Business Partnership
Luckily, in the summer of 2018, friends invited our CEO Andriy Zhylenko to Burning Man. Around the Central Camp, Andriy met Max Fateev, an old-time acquaintance from the Seattle software cluster. Max had dedicated more than a decade of his career to software development at Amazon, Microsoft, and Google. When he met Andriy at Burning Man, Max was working on Cadence – the fault-oblivious stateful code platform for Uber. If there’s anything you can’t have when running the largest taxi app in the world, it’s faults and delays.
After leaving Uber, Mr. Fateev started Temporal.io with the ambitious goal of helping developers “build invincible apps”. Temporal is precisely the remedy for “the developer has not implemented proper timeout and re-queuing” situation. Here’s how it works:
Here’s the issue with Temporal that we’re working to overcome right now: it really, really requires our customers to switch to the cloud. “Temporal is intended to run in K8s; although there are options to run it as a single process — those are marked as “experimental” by the Temporal team as of January 2022. They were even more experimental in 2019 when we started our project. We’ve been testing this for half a year already,” says Serhiy Leschenko, the “godfather” of ESPF.
Running the Proof-of-Concept
After we did our initial proof-of-concept deployment, we discovered that adding Temporal to existing “on-premise” PortaSwitch installation would require 3+ additional servers (or VMs). This would provide sufficient high availability by creating a cluster and will allow handling “spikes” of provisioning activity (e.g. product change for a large group of customers). However most of the time these servers would be sitting idle, handling just a few requests per minute — which is hardly a reasonable investment in the infrastructure. The answer? Of course cloud & Kubernetes! Providing a Temporal cloud infrastructure, shared between multiple customers would allow them to “pool” the resource usage and avoid expensive and complex changes to their existing data center infrastructure
What Does Temporal Cloud Bring to the Table for Our Customers and Their Provisioning Workflows?
If an event is supposed to be sent to an external system, it will ultimately be there. By placing ESPF to Temporal Cloud we allow Temporal to handle most of the “what if” conditions described above. The programmer needs to write just a single line of code attempting to assign a data policy in PCRF. In a “PCRF down while SIM card already activated” situation Temporal will keep trying to execute it (with reasonable intervals) until either a transaction is successful or somebody changes the code. Even if the whole datacenter (where it is running) suffers a power outage – it will resume from exactly this position after a reboot.
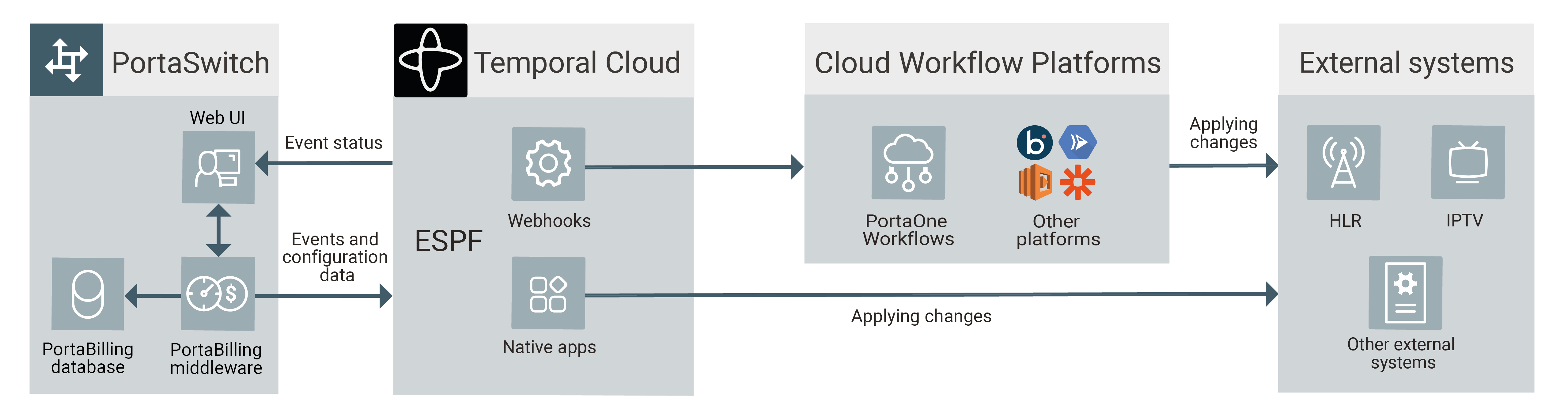
Keep in mind that Temporal doesn’t cancel webhooks altogether. It simply offers a more powerful tool (albeit one that requires some programming experience). Customers can opt in for the native provisioning apps, thus making their code run in Temporal-based ESPF. Or, they can use webhooks to “hook in” PortaOne Workflows, Boomi, Google Cloud Run, or any other cloud execution platform they like.
What’s Next? Sokoban 2.0 and Beyond: Boomi, AWS Lambda, Google Cloud Run, and All the King’s Men
There’s a lot of code running in telecom. So, making it easier to use (and reuse) by packaging it into workflows is a great solution, and not just in provisioning. The 2010s saw the simplification and “humanization” of architectures on multiple levels: provisioning, service delivery, product landings, authentication and payment methods, data processing, and BI. The code and the visual design are slowly morphing together. In 2016, Nielsen Norman Group came up with the idea of “wireflows”, a combination of wireframes and flowcharts for UX design. Now, we’re ready for a low-code and no-code transformation in provisioning workflows and elsewhere.
Here is how the PortaOne approach to low-code/no-code currently looks:
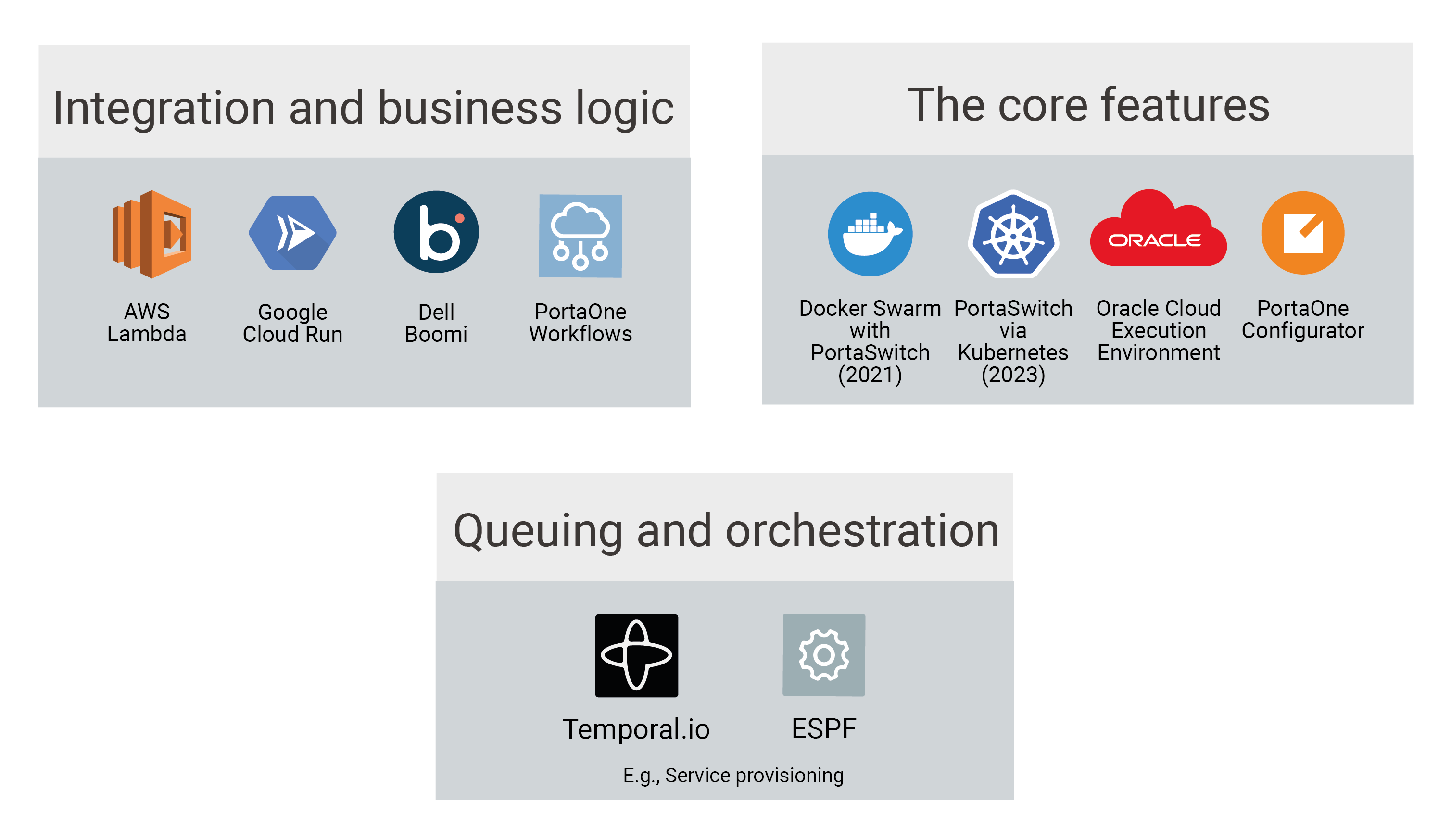
Understanding Our “Grand Scheme of Things”
Meet the Grand Scheme of Things in provisioning workflows, according to PortaOne.
We split the macro universe of PortaSwitch into three distinct layers (or stacks). First, there’s “the integration and business logic”. Next is “queuing and orchestration”. And, finally, there’s the “core”.
That first part, the “integration and business logic”, is where we enable customers to create their provisioning workflows, with minimal coding involved. Currently, our focus is PortaOne Workflows (based on Dell Boomi – the area of specialization for our “automation coach” Sergii Kirik). Still, PortaOne is platform-agnostic. And that means we can “befriend” any other low-code platform. Here, some good examples are Creatio (another successful international product with engineering roots in Ukraine) or even a “real code” running in something like Google Cloud Run, or AWS Lambda.
The gist of the “queuing and orchestration” part (that second layer) is enabling PortaSwitch to send/receive events and other billing data from external systems in a way that simplifies the further processing of that data. Finally, the “core” (layer number 3) is now undergoing substantial changes in architecture (and in code). We’ve already enabled running new code components in “on-premise” PortaSwitch via Docker Swarm. We’ve also started migrating to Kubernetes. Meanwhile, the Configurator is undergoing UI improvements. (Spoiler alert: it might as well become flow-oriented.)
To sum up the classics: PortaOne is striving to achieve a perfect enlightened state for our software architecture, in which “all the king’s horses and all the king’s men could put the service provisioning workflows together again.” Are you ready to lift your workflows into the cloud and try this “workflow programming”? If yes, please contact our sales team with your questions and get an optimized offer that fits your provisioning architecture.